Down from the metal: computer keyboards.
An introduction into fundamental software development principles by reviewing them at their origin.


We meet again, stranger!
Thank you for reading this second post in my blog about computers, software engineering and cloud applications. In the first post I introduced myself and my philosophy around coding and computer systems. This post marks the beginning in our exploration of how computers work and how humans build the incredible interactive experiences of the modern Web.
I named this blog "Down from the metal, up through the cloud, and back to the UX" because it captures the general flow of data in modern computer systems. This title will also serve as my plan for publishing articles on this blog. And so, in this article, I am getting down to the metal and exploring how human input devices capture our thoughts and ideas and transform them into electric signals useful for computers.
Computers work by performing a list of repeatable operations (a program) on some data. It is common to refer to this as Von Neumann architecture . Guaranteeing repeatability and correctness of these operations was the main problem of early computer technology as the entropy of our world tends to destroy any organized data. Von Neumann architecture addresses this problem by creating an isolated computational environment that communicates with the world only via a set of specialized input/output devices.
Many different types of input devices were invented throughout the history of computer technology. But none of them was as impactful on our world as computer keyboard, which makes exploring how it works the best starting point for learning about computers and data.
It is hard to trace who authored the source code for the first keyboard controller and driver, but it likely to be someone who worked on MIT's Multics operating system as it was the first computer system to introduce the computer terminal as we know it.
So, how do keyboards work? I will answer this question using the mobile keyboard I designed for my phone as an example. And, as a bonus for my readers, I will publish for the first time design files for this keyboard at the end of this post.
An early prototype of my mobile keyboard on the back of a Surface tablet
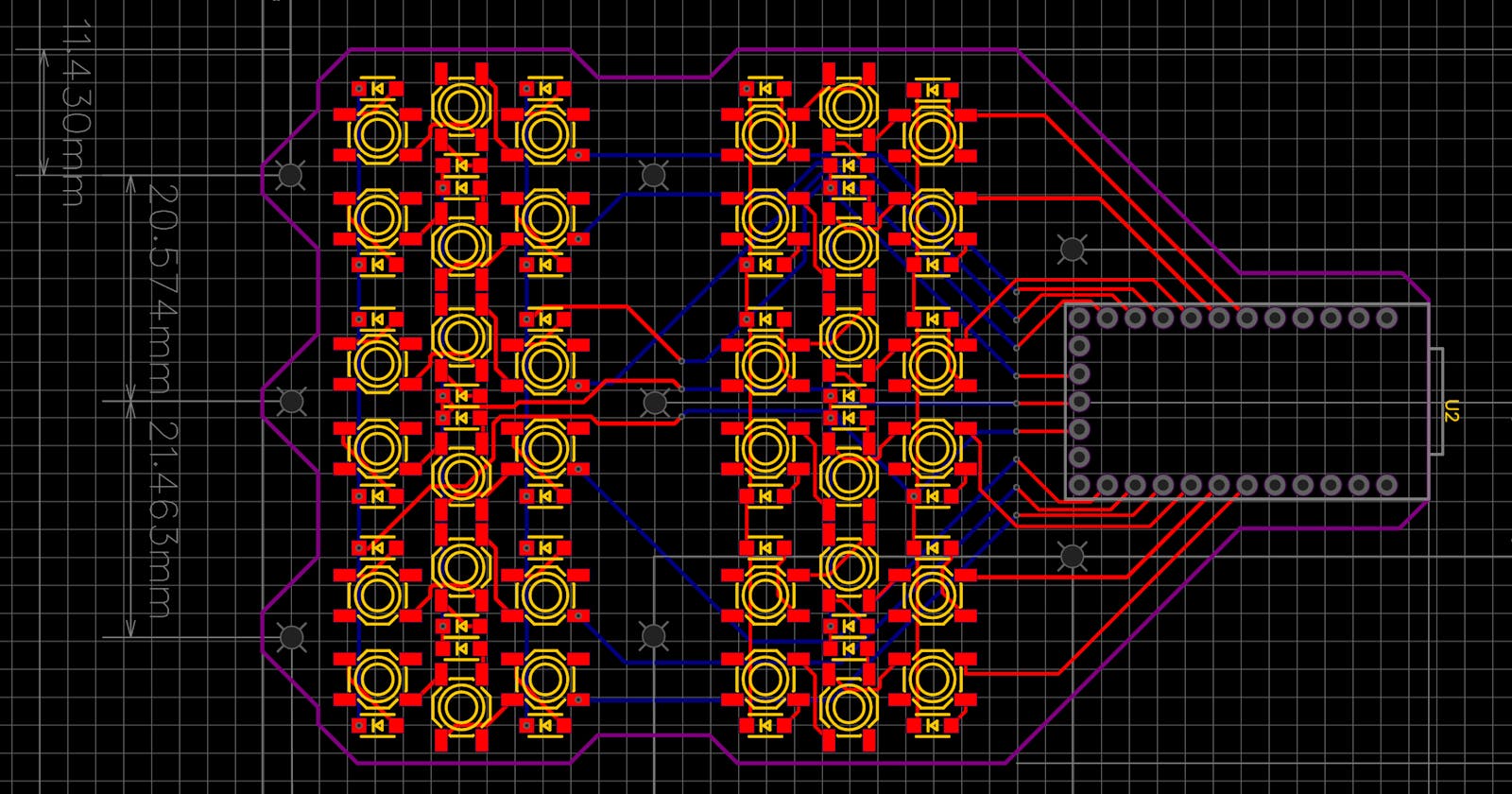
Although it may not look like any other keyboard you've seen before, it uses the same principles, technologies, and components that you may find inside of any other desktop or mobile keyboard produced in the last 40 years or so. The journey of any textual data entered by humans into a computer system can be traced to the most fundamental component of the keyboard. And so, please welcome the queen of computer technologies - the keyboard matrix .
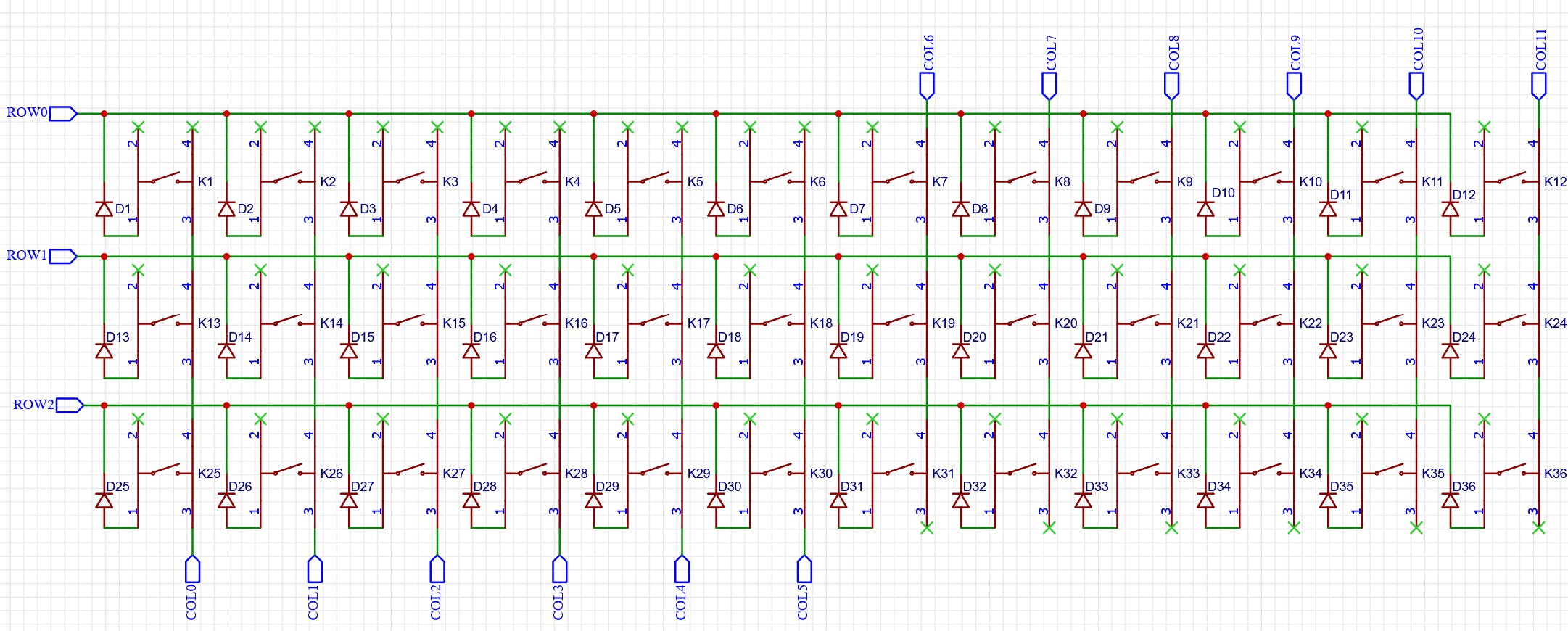
A keyboard matrix is an electrical circuit that allows computers to capture the state of multiple keyboard keys arranged into rows and columns. It may seem excessive and too complex to people somewhat familiar with analog electrical circuits. Some of my readers may even wonder why can't the keys be connected directly to the computer as you'd see on the classic electric circuit that shows a single switch and a bulb. Although it is possible to build a keyboard by connecting the keys directly to a microcontroller, such a solution requires more connections to the controller, and using more pins (points of electrical connection between the controller and its circuit) means using either more complex and more expensive microcontrollers or, alternatively, more less powerful microcontrollers (which ends up being even more expensive than using a single more capable controller). There are other hardware design problems that affect reliability of such a design, but diving into them is out of scope for this post.
For example, one of the most popular microcontrollers, the ATMega32u, has 4 8-bit GPIO ports, which results in 32 pins available to the designer. One would need at least five ATMega32u to read the state of a regular keyboard if the keys were connected directly to the controller, while arranging keys in a matrix pattern allows one to read the same state with just a single microchip.
To be able to read the state of the keyboard keys, a microcontroller needs to know how exactly is it connected to every key of the keyboard. This is where keyboard firmware first comes into the picture. The basic element of any keyboard firmware is the matrix scanning loop, during which the state of every key is read and stored into the microcontroller's memory.
The matrix state, however, does not represent the information a user enters on their keyboard because such a state is just a snapshot in time. All it can tell us is that some of the keys are pressed while others are not, but it tells us nothing about the order in which these keys are pressed. The information we enter using our keyboards is retrieved by the keyboard firmware by continuously comparing these snapshots to each other. Only by looking at the changes between these snapshots the firmware can detect what exactly and in which order was entered by the user. And it is these changes, not raw matrix states, that microcontroller's firmware sends to the computer that keyboard is connected to. When you press a key, it changes the state of the keyboard matrix that is read into the microcontroller's memory. Comparing this new state with the previous allows the firmware to detect a keypress and report it up to the computer.
Calculated by the firmware matrix state changes are usually sent to the computer using a special set of predefined codes called scan codes. Every time a new matrix state change is detected and its scan code is calculated, the keyboard firmware notifies your computer about such a change. For example, one scan code can be used to notify your computer that the "A" key was pressed on your keyboard, while another will be used when it is released. Different protocols and transfer mediums can be used to send these changes and reviewing them all is well beyond the scope of this article. Instead, I will describe this process in general terms of x86 architecture and will leave a more detailed review of HID protocols for future articles.
In x86 as well as in many other architectures every input or output device is connected to the main CPU of your computer via input/output ports, repeating the same pattern we saw when talking about microcontroller pins. When keyboard firmware wants to send a new scan code to the computer it sets the port through which it is connected to the computer into a special state. In the real mode of x86 architecture, such a change results in a special kind of event called an interrupt. It is called that way because in early computers handling such an event would involve interrupting the currently running application by switching the CPU to execute the event handler.
A keyboard interrupt handler, when invoked, would read sent by the keyboard firmware scan code from the port and put it into the computer's keyboard input buffer, from where it can be later read by the computer's operating system or a user application, which would process the scan code either by transforming it back into entered by the user text or handle it in some different way. In a sense, the only job of the interrupt handler is to ensure that data flows from the keyboard into the system buffer without being lost or corrupt in the process.
Describing how user input is handled inside of an OS is, however, a topic for a whole different article that will continue our journey through computer technologies later. But to prepare us and make these next steps easier, I want to finish this article by providing you a bigger picture of the keyboard input subsystem and pointing out the long-reaching implications that can be drawn from such an overview. The easiest way to do so is to represent the keyboard subsystem as a set of layers through which the data you enter has to travel to reach your computer:
A simplified overview of a typical keyboard data pipeline
Understanding general principles of how computer keyboards work is very helpful to understanding how modern computer systems work. By guiding our journey to the first glimpse into what data is and how it wants to be handled it shifts our focus from learning algorithms to learning about how data behaves inside computer systems. It shows us that, on the lowest levels, data is not just a set of bits and bytes. Instead, it is more beneficial to think of information as history of changes that some system (in this example - the circuitry of a keyboard) goes over time. This view is not limited only to textual data and is also applicable to audio and video: audio information describes changes in air density of a system and video information most often describes changes in visible part of electromagnetic spectrum.
Although knowing how keyboards work is not required to be a coder, going through this showed us some fundamental properties of information that dictate how modern computer systems are built:
Any data processed by a computer can be viewed as a stream of changes of some state over time. Thus, one can say that data is not simply operated upon or stored by computers but that it flows through computer circuits in the form of events and electrical signals. As it flows through the system, data goes through different layers of logic and causes that system to change its state. Every logic layer analyzes the data that flows through it and adds more meaning to it. This additional meaning is used then by higher levels to either perform some action or to add even more meaning to the data. Therefore, engineering computer systems comes down to designing these layers and adding more meaning to data as it flows through the system. This pattern governs how all computer systems behave and can be observed in every single one of them. The OSI network model, a cornerstone technology of the Web that I will review in one of the next articles, is a great example of a system design that uses these principles with great success.
Even if you don't write firmware or device drivers and your work is mostly concentrated in building web applications, adopting this datacentric view and promoting data and its flow to the center of your thinking about a computer system will allow you to avoid many bugs and performance bottlenecks and design better computer systems, be it a simple calculator application or a complex decentralized social network that runs on millions of physical nodes built with different internal designs.
Please stay tuned for the next article "Down from the metal: making sense of the input", in which I plan to go over how computers parse keyboard (or any other) input and use it to react to the changes in the surrounding world and satisfy requests from their users.